

To ensure that your website is visible on Google, the search engine needs to be able to find your content, read it, and understand it. In addition, it’s crucial for your site to offer a user-friendly experience, whether visitors are using a desktop, mobile phone, or tablet.
Technical SEO is a collection of methods and activities designed to optimize your website for aspects such as:
- Crawling and indexing: Make sure Google can find all your important pages and indexes them (adds the content to its database “Google Index”).
- Speed: Ensure that the website loads quickly.
- Mobile friendliness: Ensure the site is user-friendly on mobile phones.
- Structured data: Apply structured data to help Google better understand your content.
One could say that technical SEO sets the stage for all your other SEO projects to be fruitful. No matter how excellent your content is, your website will never reach the top of Google without a solid technical foundation.
In this guide, we will walk you through the various areas and what you can do to get all the pieces in place.
Table of Contents
How does Google find content?
To access content on the web, Google uses a program (web crawler) known as Googlebot.
Googlebot searches through (crawls) all the content it encounters and copies it to a massive database – the Google index.
When someone searches on Google, the results are retrieved from the index and displayed in Google’s search results.
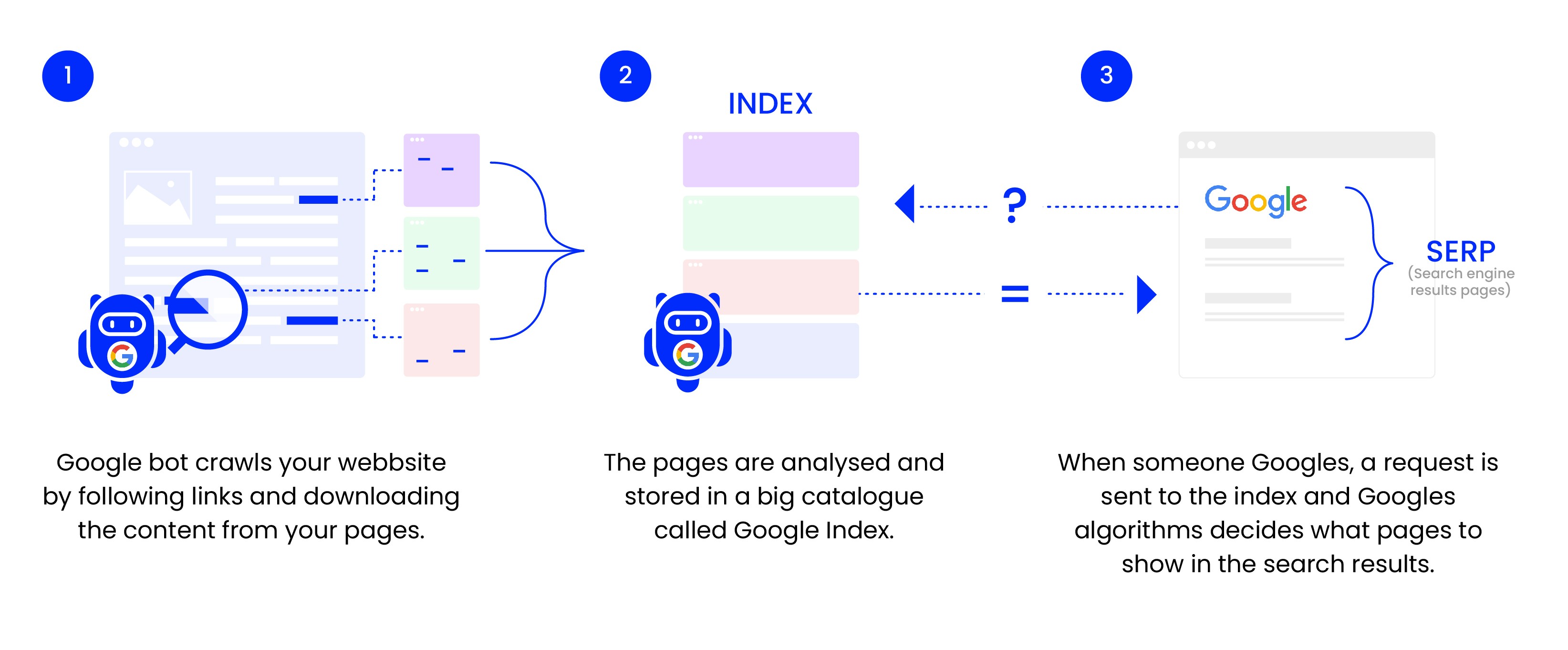
Crawling
Googlebot crawls the web by visiting and reading pages and then navigating further via the links it encounters. This way, it maps out the internet, the relationships between pages on websites, and how they relate to other external sites.
It’s essential to ensure that Googlebot can access all the pages you want users to find when they search on Google. To enable this, you need to create internal links between the pages. More on this below.
If your website is brand new, first you need to introduce your website to the crawler.
How to introduce your website to Googlebot
For Googlebot to crawl your website, it needs to find the site, which it can do in three ways:
- Submit a sitemap to Google
- Ask Google to index your website
- Another website Googlebot crawls links to your website
You can’t force anyone to link to you, so the safest (and simplest) method is to upload a sitemap and/or ask Google to index your website. You can do this using Google Search Console (GSC) – a free tool which you connect to your website.
Source: Google Search Console’s landing page
Uploading a sitemap in GSC
A sitemap is a map of the pages on your website you want Googlebot to visit. In practice, it’s a long list of URLs Google can read.
Most CMS systems can generate sitemaps automatically with the right add-ons or settings.

Here’s what Klikko’s sitemap looks like, generated by Yoast SEO
You may already have a sitemap, which you often find under:
yourwebsite.com/sitemap.xml
yourwebsite.com/sitemap_index.xml
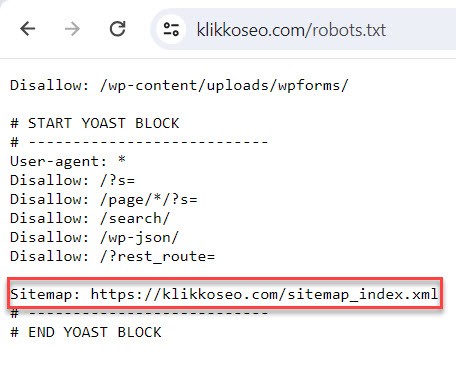
You can also check your robots.txt file, where the sitemap is often included. Find the robots.txt file here:
yourwebsite.com/robots.txt
If you haven’t found your sitemap yet, you can try using Google Search Operators. Enter the following line in the web browser:
“site:yourwebsite.com filetype:xml”
If you still can’t find your sitemap, check the documentation from your CMS on where sitemaps are stored.
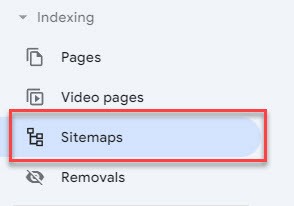
Once you’ve located your sitemap, upload it via GSC by clicking “Sitemaps” in the sidebar:
Then paste your sitemap’s address and click “submit”:

It may take a few days before Google processes and accepts the sitemap. Once finalized, the tool will provide insight into which pages Google has found and importantly, which ones it has chosen to index (or not).
Request indexing in GSC
Using the URL inspection tool in GSC, you can ask Google to index specific URLs. Enter your homepage here:

Then you can ask Google to index the webpage:
Google will visit the webpage and, if you have a functioning internal link structure, crawl the rest of the site and hopefully index the content. We’ll revisit indexing later.
Website structure and internal links
Google appreciates easy-to-navigate websites, just like any visitor. Ideally, each page should be accessed with as few clicks as possible from the homepage. This is facilitated by a flat and logical website structure.
A good solution is to create a clear category structure with main categories linking to relevant subcategories, which in turn link to products and services. The simplest way to illustrate this is with an example from a hypothetical webshop selling home electronics:
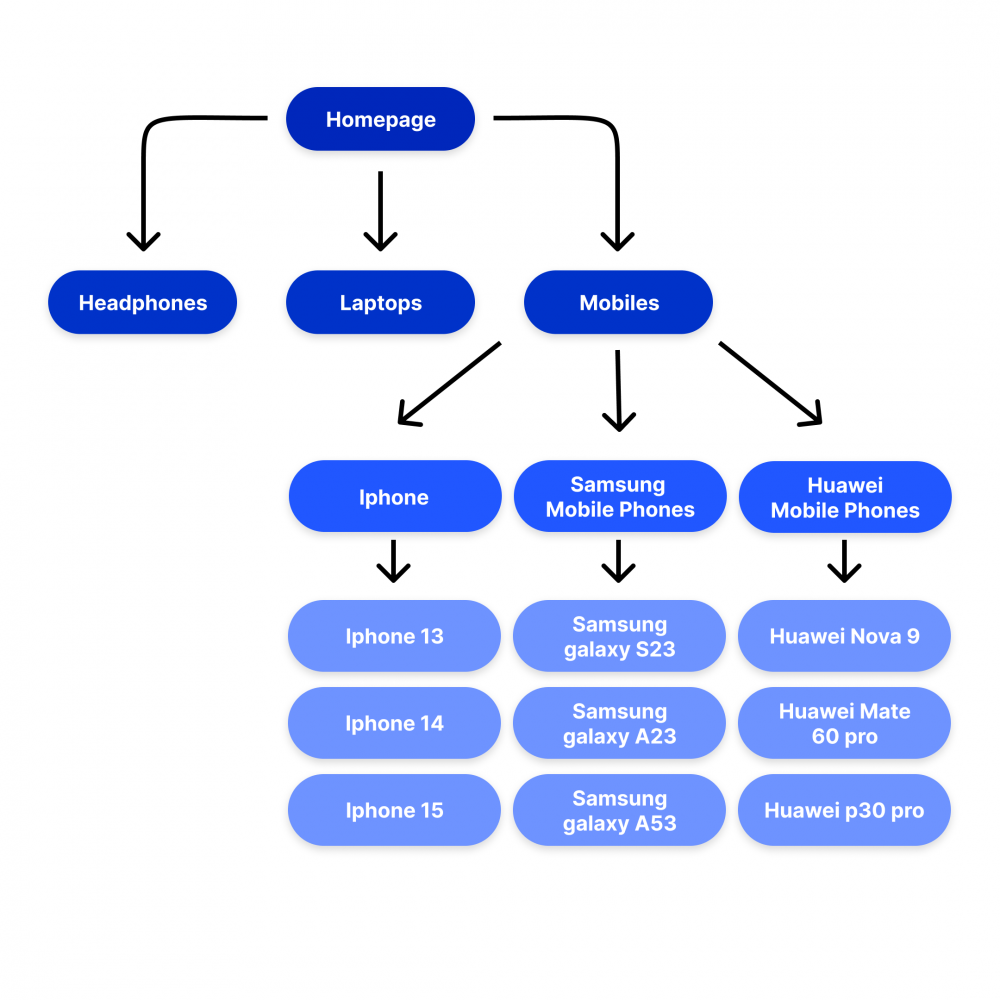
With this structure, it becomes easy for both a visitor and Google to logically progress from the homepage to the product by clicking on:
- Main category (Mobile phones)
- Subcategory (Brand)
- Product (Specific phone)
All products are accessible within three clicks from the homepage, which is a good click depth. You don’t want to bury pages too deep on your website, which neither Google nor users appreciate.
NOTE: It’s often a good idea to already display products under the main category. For example, all phones in the mobiles category in the structure above. See below to get an idea of how that might look in reality:
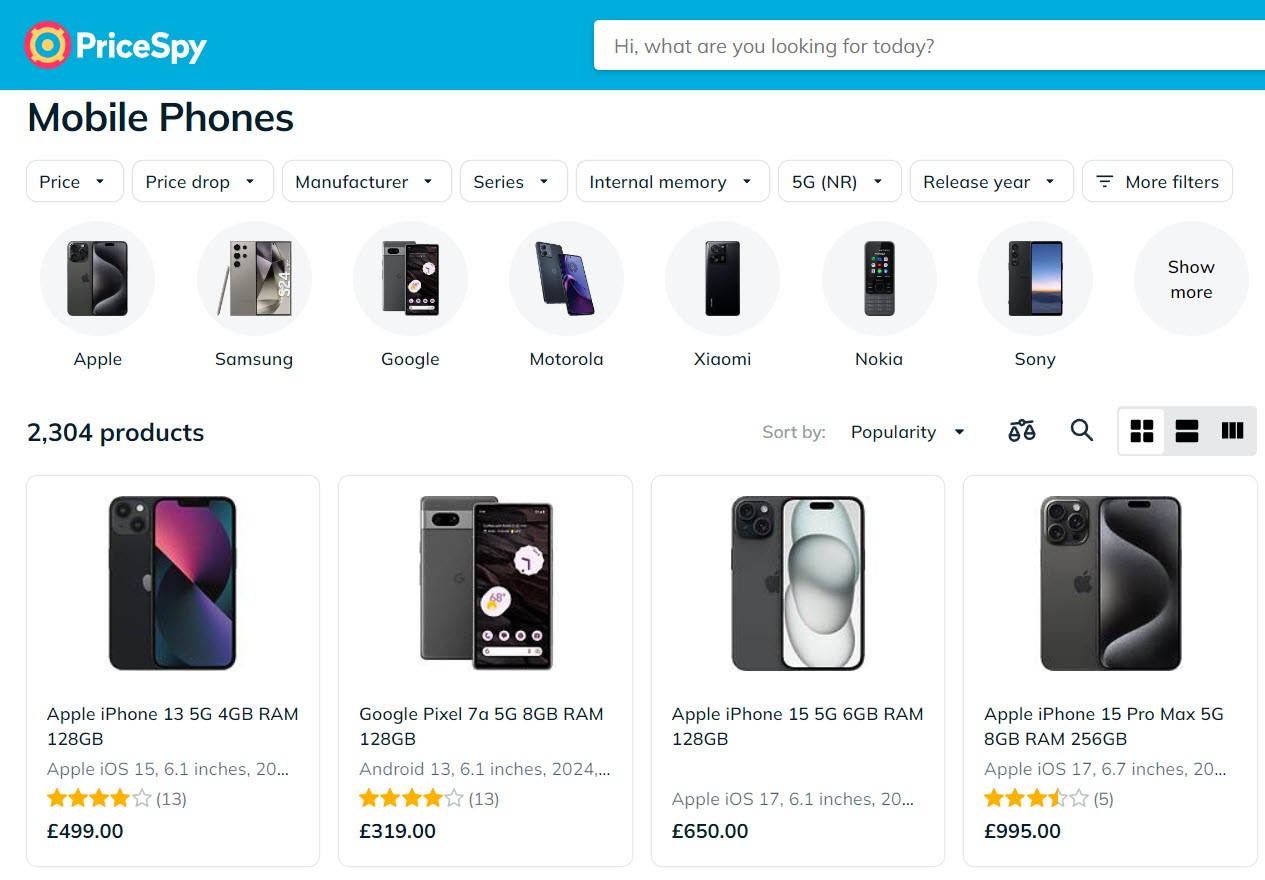
A good category structure by pricespy.com
With a clear structure and hierarchy, it becomes easy to create new pages and place them correctly. It also minimizes the risk of creating orphaned pages, i.e., pages without a link. If pages don’t have links, they might not be indexed, even if they’re included in your sitemap. And even if they’re indexed, their lack of internal links is a negative ranking signal for Google.
How to create a good structure
Visualize your pages, how they interconnect, and then create a categorization. This applies to both e-commerce sites and service providers. For example, a law firm could have business law and private law as main categories. Beneath them, they could entail:
Business law – Employment law, contract law, commercial disputes, and more
Private law – Family law, migration law, consumer disputes, and more
Under family law, even more specific services could exist, such as powers of attorney, divorce, custody disputes, and more.
To help visitors with informative content, they could also have an independent blog. Then the final structure would look like this:
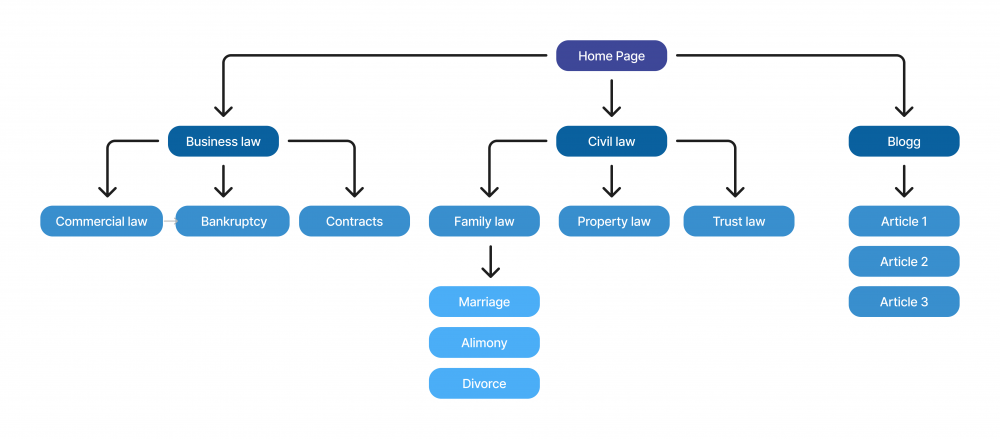
All pages are accessible via a maximum of three clicks from the homepage, and the structure is user-friendly.
By creating this type of structure for your website, Google will easily be able to crawl and understand the relationships between pages.
When you have your structure and sitemap in place, it’s time to understand how and if Google indexes your website.
Indexing
Indexing is the method Google uses to store and organize the pages it has crawled. However, just because Google crawls your pages, it doesn’t guarantee that they will be added to the index.
You can check if your pages are being indexed in various ways:
1. Google Site Operator
Open a browser and type the following in the search field:
site:yourwebsite.com
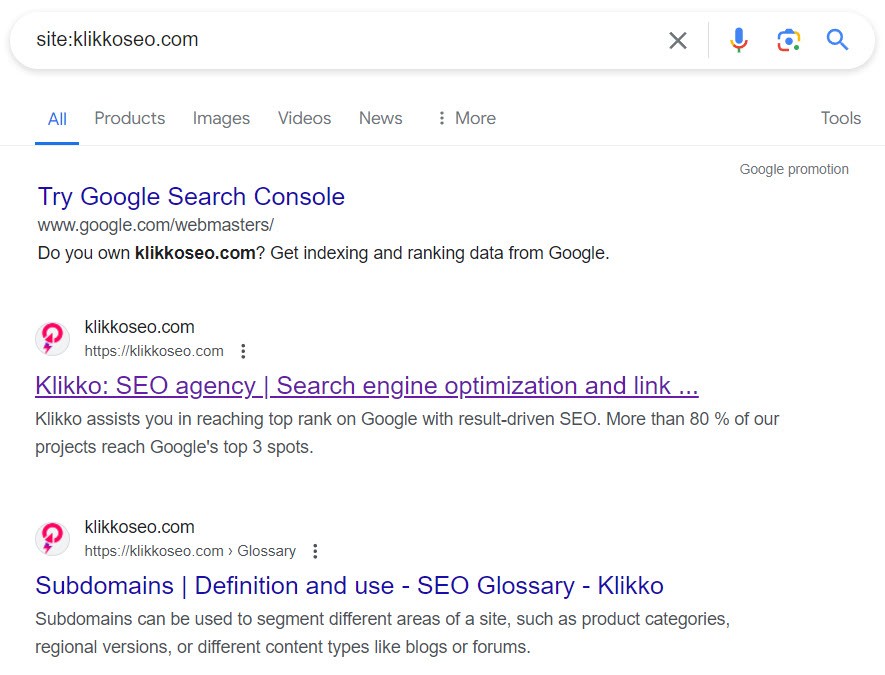
This will give you an approximate list of all URLs Google has indexed from your site.
You can also see if a specific URL is indexed by typing it after the site operator:
site:yourwebsite.com/specific-url
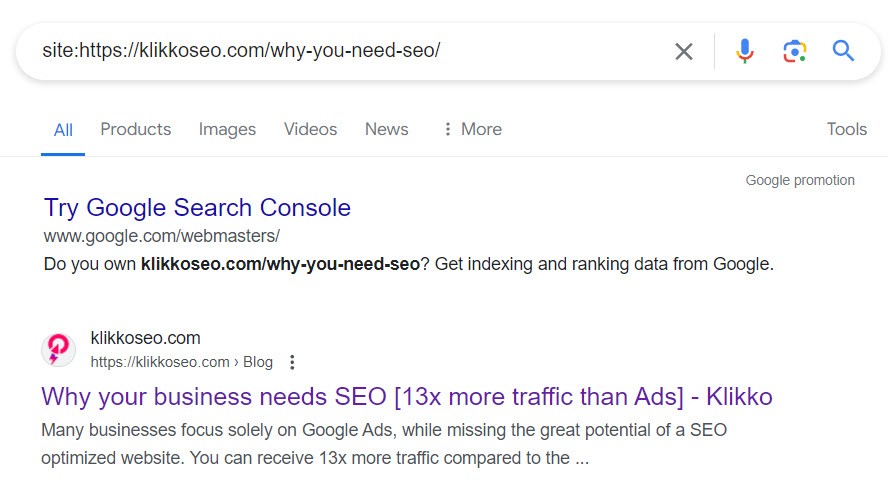
2. URL Inspection Tool
In Google Search Console, you can enter the full URL you want to check in the “URL Inspection Tool,” and the tool will tell you if the page is indexed or not.
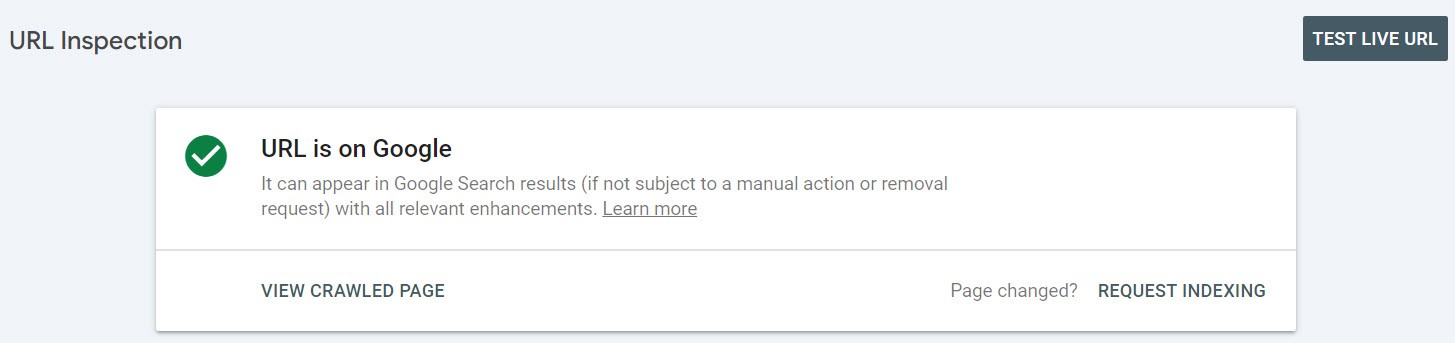
The page is indexed
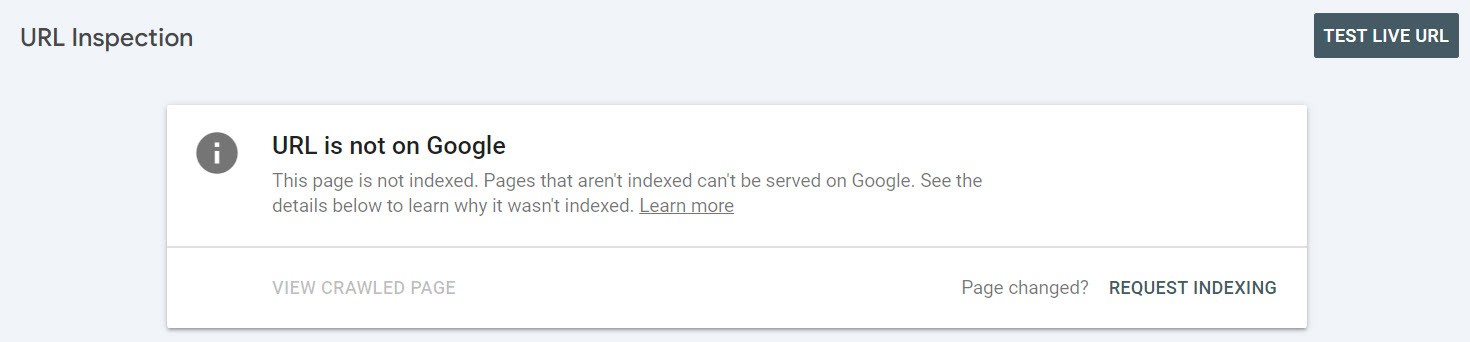
The page is not indexed
The tool can also provide information as to the reason why pages are not indexed. This is useful when troubleshooting and fixing indexing issues:
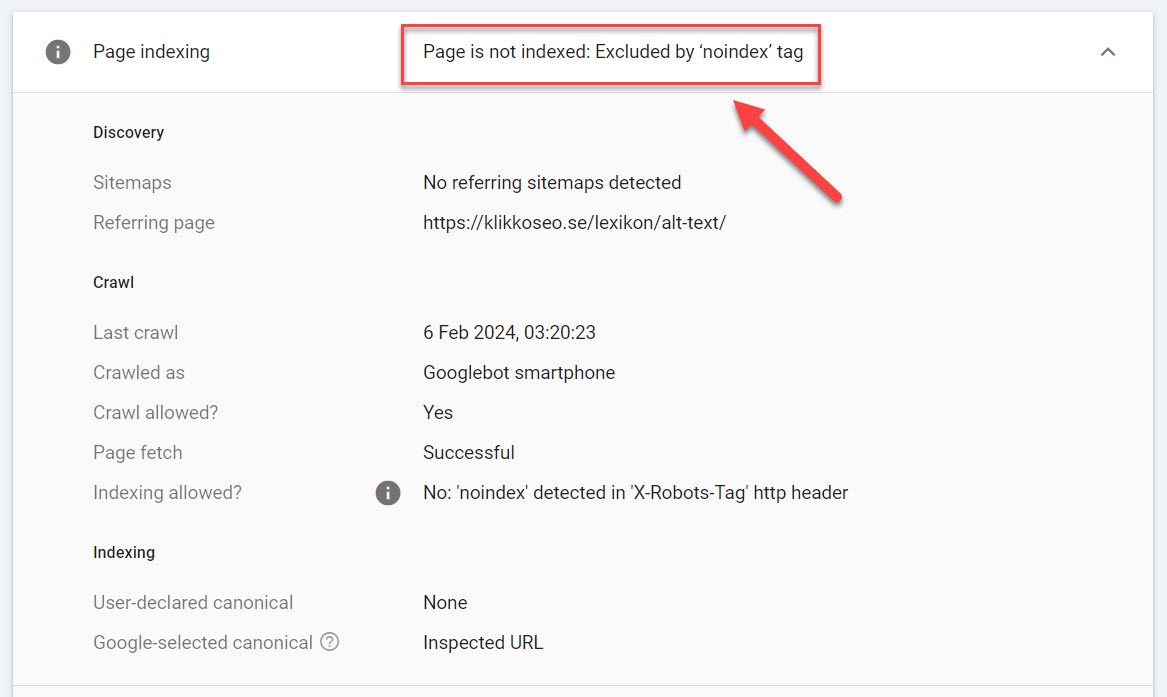
Causes behind the page not being indexed
3. Pages report
In the Google Search Console, you can also find the “Pages” function under “Indexing”. Here you can see all the pages Google has found on your website and whether they are indexed or not.
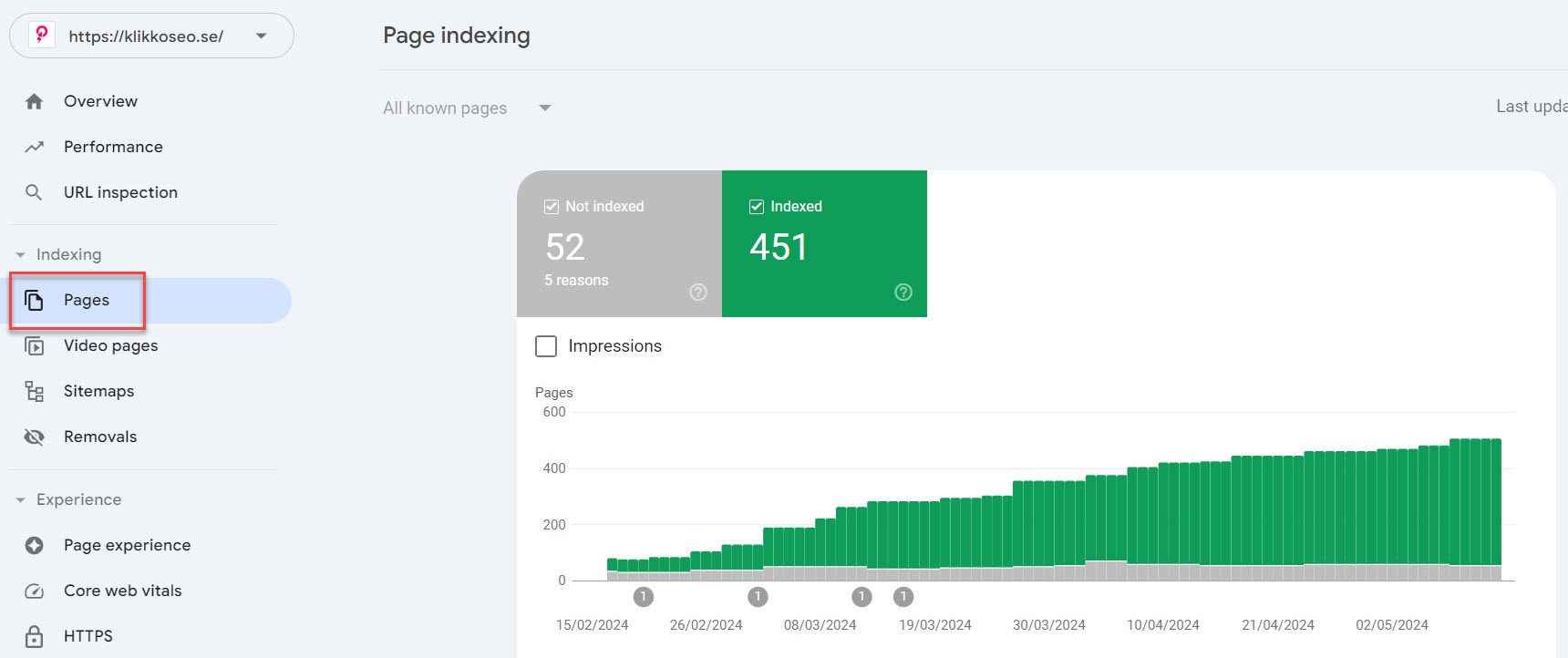
Addressing indexing issues
In a way, you have to be a detective to figure out why your pages aren’t indexed. Luckily there are excellent tools out there to help you:
- Google Search Console (GSC) – Free for all website owners
- External tools – Third-party tools that crawl your website and identify issues. The most well-known (and for good reason) is Screaming Frog
Identifying indexing issues with GSC
The “Indexing” page in Google Search Console provides reports on the pages on your website that Google knows about and whether they are indexed or not.
In a graph found in “Pages”, you see how many pages Google is aware of and their indexing status. If you scroll further down, you’ll find a list of any indexing problems and which pages that are affected by each problem respectively:
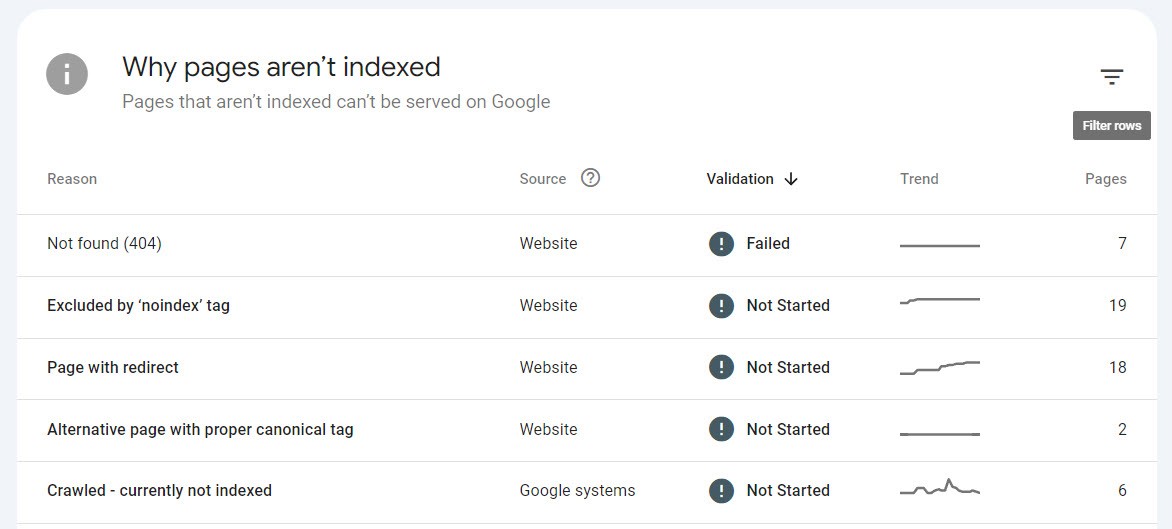
Not all reasons for not being indexed are actual problems; redirections, canonicalized, or “noindex” pages may be deliberate and correct.
It’s important to review different “reasons” to ensure they are in order and correct the errors you find. This could be anything ranging from incorrect redirects, 404 pages with inbound links, or pages which have been crawled but not indexed.
Other analytical tools
After correcting all the errors you found in GSC, it’s a good idea to run the site through an external tool to close any gaps. There is a plethora of good options on the market. Among others, Ahrefs and SEMRush are tools providing technical- as well as keyword- and backlink analyses.
We mainly recommend Screaming Frog, which is a tool dedicated to finding technical errors and potential opportunities on your website. Enter your homepage into the tool to get a detailed list of problems and how to solve them. It’s invaluable if you work with technical SEO.
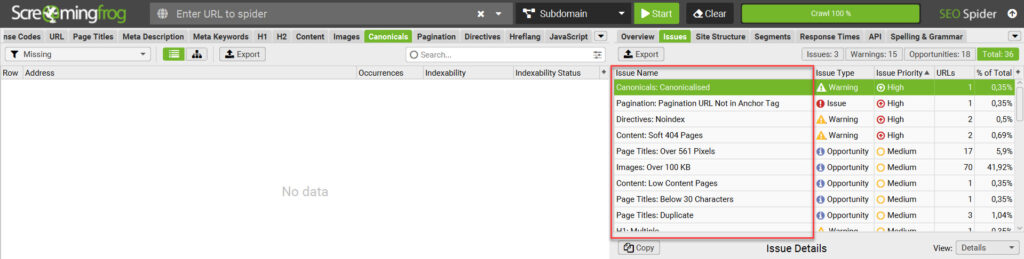
Screaming Frog (identified issues highlighted in red)
It’s especially the problems marked with “High” or “Medium” priority that you should focus on. Address these promptly.
Common indexing issues and how to resolve them
There are many possible reasons as to why Google chooses not to index pages on your website. We can’t go through them all, but some common issues include:
- 404 pages
- Incorrect redirects
- Incorrect noindex tags
- Blocked by robots.txt
- Duplicate content
404 – Not found
404 is an error code generated when a link refers to a non-existing page. This is bad for users and Google alike. Depending on the context, it can be solved in various ways, including:
- Misspelled – If the URL in the link/links to the 404 page is misspelled, correct it everywhere.
- Removed by mistake – If the page is removed by mistake, restore it.
- Moved – If the page has a new address, for example, if examplewebsite.com/top-10-products/ has moved to examplewebsite.com/guides/top-10-products/, set up a redirect from the old page to the new. Redirect links from the old page to the new.
- Permanently removed – If the page is permanently removed intentionally, consider whether it might be relevant to redirect the page to another appropriate page. Then also make sure to redirect the links to the new page instead. Alternatively, remove all links pointing to the incorrect page from the website and sitemap.
Bonus: Your visitors will encounter 404 pages, whether you like it or not. Maybe they type an incorrect address when trying to visit one of your pages. It can be a good idea to have as pleasant and user-friendly an experience as possible when users encounter 404 issues.
Source: A clever 404 page by marvel.com
You can design your own 404 page, wherein it would be ideal to include links to popular categories and products.
Incorrect redirects
A redirect directs a visitor or bot from one page to another. It’s often used when content is moved from one URL to a new one. Problems with redirects can arise for different reasons, which ultimately lead to Google not indexing the final target page:
- Excessively long redirect chains – A URL redirects to a new one, which in turn redirects to another URL, which redirects to another, and so on. If the chain gets too long, Google will eventually give up on following it. The solution is to simply minimize the number of redirects, ideally, all links should point to pages which are NOT redirected.
- Redirect loops – A URL redirects to a URL or a chain of redirects, which ultimately redirects back to the original URL. This creates an endless loop ending in an error message for the visitor or bot. The solution is to redirect all URLs to the desired page and ensure all links on the site point to the same.
- Redirect chain with a faulty or empty URL – When a redirect chain contains a faulty or empty URL making it inaccessible. Correct the incorrect URL, but also make sure to point all redirects to the correct URL and make sure all links on the site point to it.
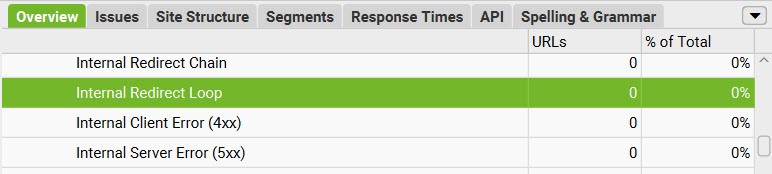
Source: Screaming Frog identifies redirect chains and loops
Incorrect noindex tags
Noindex is a directive telling Google to not index a page. Sometimes, pages which should be indexed are mistakenly labelled with a noindex tag. To solve this, simply remove the noindex tag.

How the noindex tag looks in code
Blocked by robots.txt
Sometimes webmasters accidentally block critical pages or resources in their robots.txt file. Review the instructions in the file so they do not block Googlebot from the pages you want to have indexed.
Duplicate content
Duplicate content means you have pages on your site almost- or entirely identical to each other. Or even worse, if you’ve copied content straight from an external website.
Duplicate content can appear due to various factor, but regardless, it can have undesirable consequences if not handled properly:
- Google finds it difficult to determine which content to index. It can lead to different pages replacing each other in search results for the same search.
- Google may choose to downrank pages or even refuse to index pages with duplicated content.
There are different ways to identify if you have duplicate content.
- In GSC, you can see warnings for when Google has found duplicate content on your website and how they relate to it. You’ll find them under indexing – pages in the report “Why pages aren’t indexed”. Look for:
- Duplicate without user-selected canonical
- Duplicate, Google chose a different canonical than user
- Duplicate, submitted URL not selected as canonical
- There are several tools that can identify duplicate content, including Ahrefs, SEMRush, and Screaming Frog.
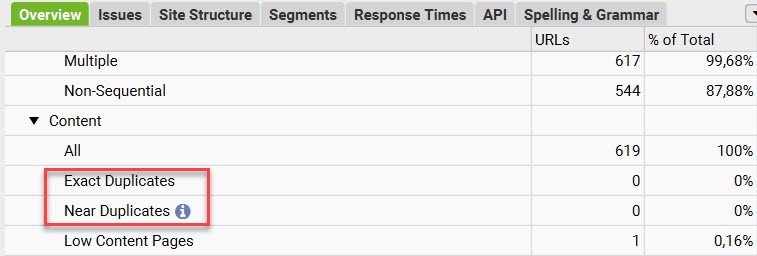
Identify duplicate content in Screaming Frog
If you notice that you have duplicate content, there are different ways to fix the problems: Redirect, Noindex, or Canonical. The best-fitting solution depends on the context.
- Redirects can be useful if you notice that you accidentally created a duplicate of a page which doesn’t add any value where it’s currently placed. Set up a redirect and redirect all links pointing to the duplicate to the original.
- Noindex can be a solution for duplicate content that is useful for visitors, such as all tag- and category pages generated by your CMS (common in WordPress). They have no unique content but are used for navigation.
- Canonical is a directive for Google indicating another URL as the main version of the page. It can be used for almost identical product pages on an e-commerce site, for example. If you have a page for a dress and four linked pages for different color options, the color pages could use canonical tags pointing to the main page.
Best practice after fixes
After you’ve carried out an action on your website, it’s a good idea to verify that it works as it should. Screaming Frog is perfect for this. If you’ve already done a crawl of your site in the tool, you can compare the initial crawl with the new one.
Then go to Google Search Console, open “Pages” and click on the problem you’re fixing followed by “Validate Fix”.
Note: It may take a while before Google verifies whether the action went through.
If you’ve followed the guide, you’ve now achieved the following:
- A flat site structure and links to all the pages you want Google and users to see.
- Uploaded your sitemap via Google Search Console.
- Corrected errors preventing Google from indexing your pages correctly.
Congratulations! You’ve just created a good foundation for Google to crawl and index your pages. It’s time for us to take a closer look at the next technical aspect highly valued by Google: speed.
PageSpeed and SEO
PageSpeed is a direct ranking factor which affects your website’s ranking in search results. Like all other ranking factors, however, we don’t know how much influence it has.
Statistics show that the slower a webpage loads, the higher the risk is of a user losing patience and “bouncing”. That means they leave the page without interacting with it (and in the worst case, go to a competitor). Google notes user behavior and if they see a pattern of visitors quickly leaving your page, you risk losing positions in search results.
Fact: The risk of getting a bounce increases by a whole 32% if the page goes from a load time of 1 second to 3 seconds.
How do you optimize your PageSpeed?
The first thing you should do is test your website in Google’s PageSpeed Insights, which is a free tool from Google. You can analyze one URL at a time, and the tool shows you your current status and a variety of improvement areas within speed, UX, and SEO.
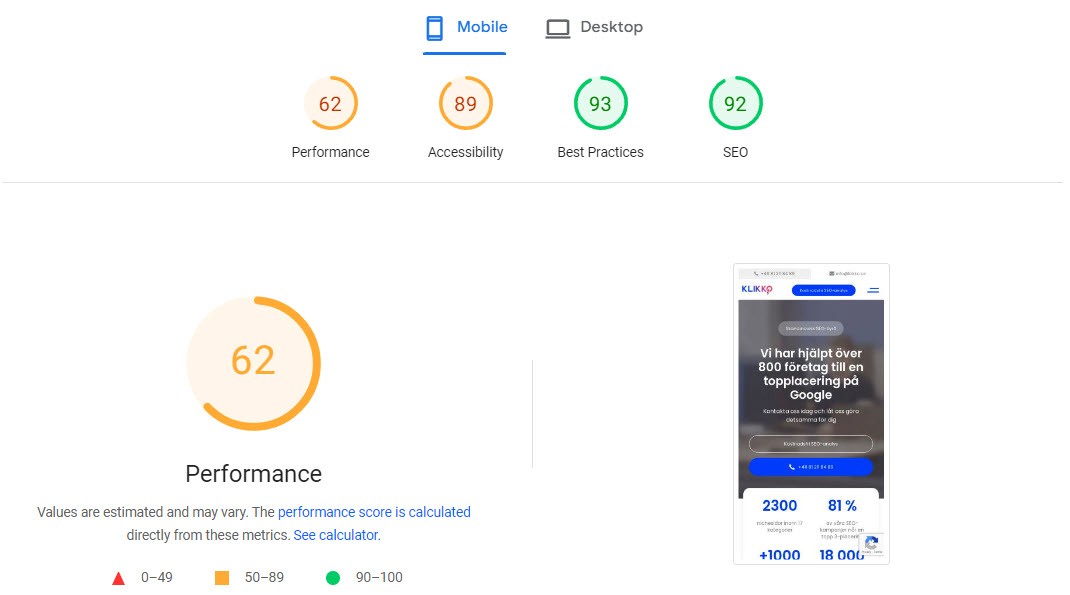
It also gives you tips on what to improve and how to improve different parts of the webpage.
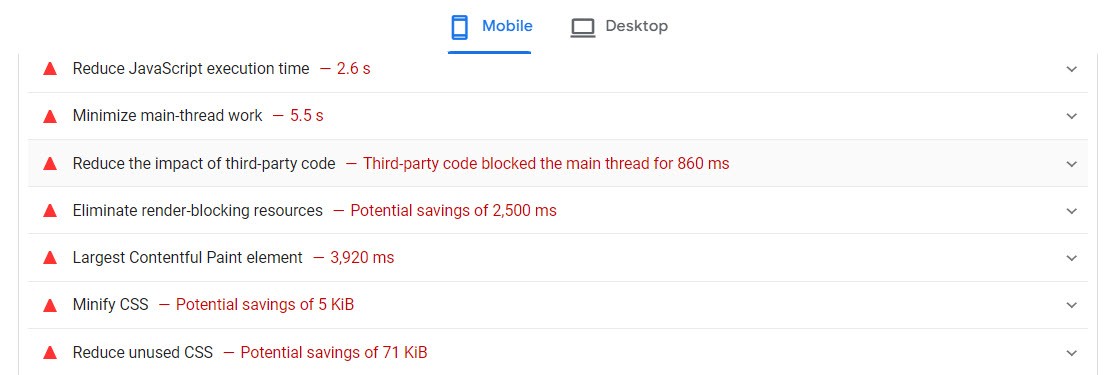
There are a variety of aspects on a website that affecting loading times and we can’t list them all here. Common methods to speed up your site include:
Compress files
Use compression software/formats like gzip to compress CSS, HTML, and JavaScript files larger than 150 bytes. But don’t use this for images.
Try to minimize images (without compromising on quality) with programs like Photoshop or free services like TinyPNG.
TinyPNG
Different image formats are suitable for different types of images:
JPG – Best for photographs
PNG – Best for graphics, design elements, and logos
Reduce redirects
Every redirect slows down the load time for the visitor, so avoid unnecessary redirects and particularly long redirect chains (as we’ve talked about above).
Use a CDN
CDNs, or Content Delivery Networks, are a group of servers distributed over a wider geographic area. They store a cached version of your website to provide visitors closer to the CDN server with a quicker and more reliable access to the site.
Minimize CSS, JavaScript, and HTML
Optimize the code, by for example removing unnecessary:
- Spaces
- Commas and other redundant characters
- Comments
- Unused code
Reduce HTTP requests
The more files a browser needs to request from the server hosting your website, the slower the load time. This includes files such as images, embedded videos, unnecessary plugins, and etc. Go through your pages and see if all the resources really contribute to the experience and if you have superfluous plugins installed.
You can also use lazy loading, which means that content isn’t loaded until the user has scrolled to the area of the page where the content is located.
External tools
In addition to PageSpeed insights, there are several tools analyzing website speeds on a deeper level, including GTMetrix and WebPageTest
Mobile friendliness
In Fall 2016, Google launched the Mobile First Indexing initiative, which means they use the mobile version of a site to crawl and index it. Seven years later, in 2023, they finished implementing, leading to the desktop version of Googlebot becoming obsolete.
Source: Google
Why?
Because the majority of the global population use the phone when looking for information on the web.
What are the implications?
Practically speaking, the mobile first framework means that it doesn’t matter if your page is amazing on the desktop, if it doesn’t work on mobile. Googlebot only cares about the mobile version.
How do you optimize for mobile first?
Above all, you should ensure the content on mobile and desktop is the same. The most common solution for this is implementing responsive design on the website, which is standard for most sites today.
Many neglect to use the mobile version as the starting point when they develop websites and new pages. In all likelihood, it is the mobile version of your page with which the majority of users will interact.
Even if pages are designed on desktop, make sure to primarily assess how the result will look on mobile. There are various tools, like BrowserStack,you can use to see how a website appears on different device types.
A free and easy way to quickly check how your site looks on mobile is to use Google Chrome’s “Inspect” feature (right-click anywhere on the website):
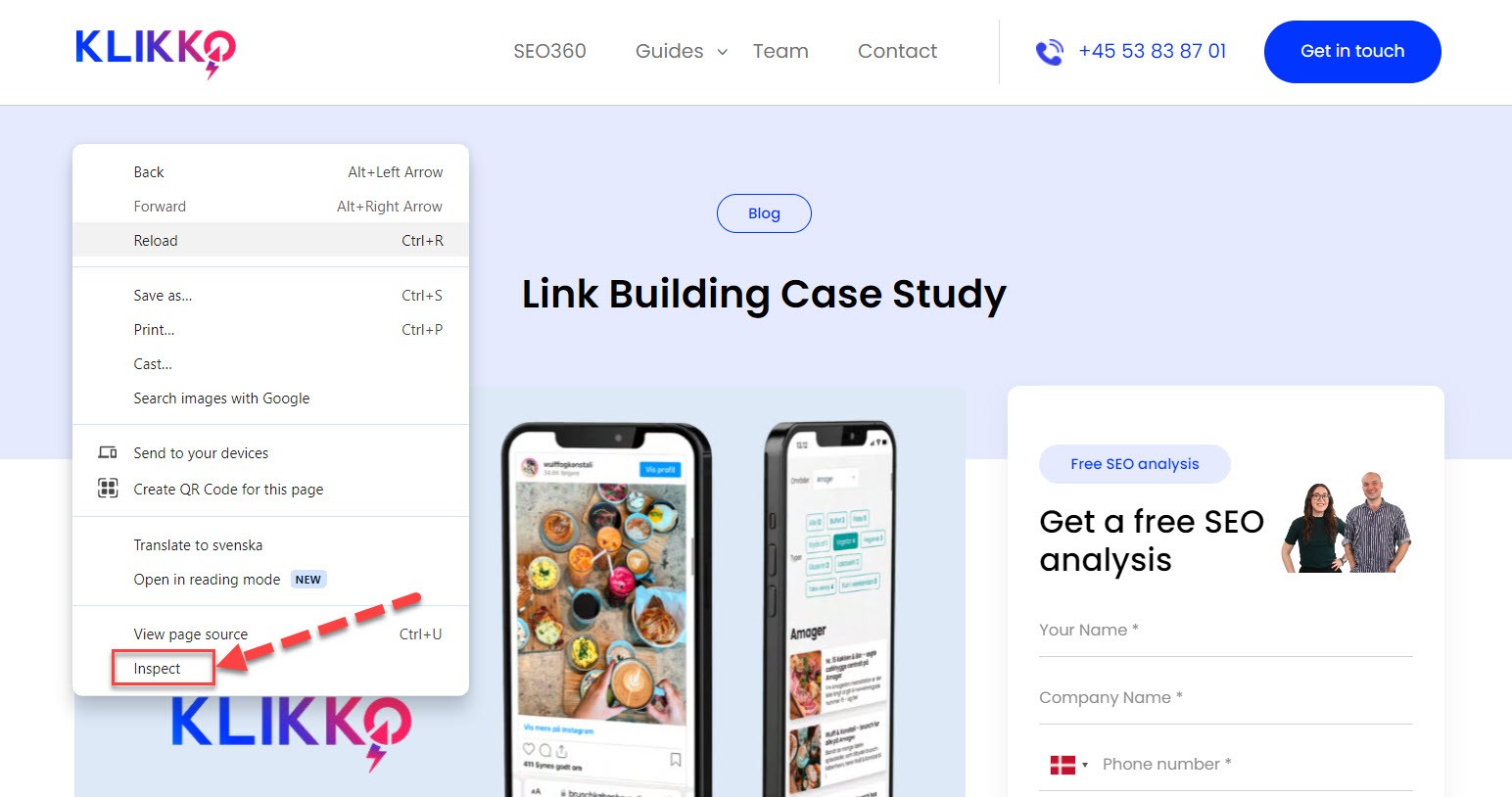
Then toggle to mobile view here:
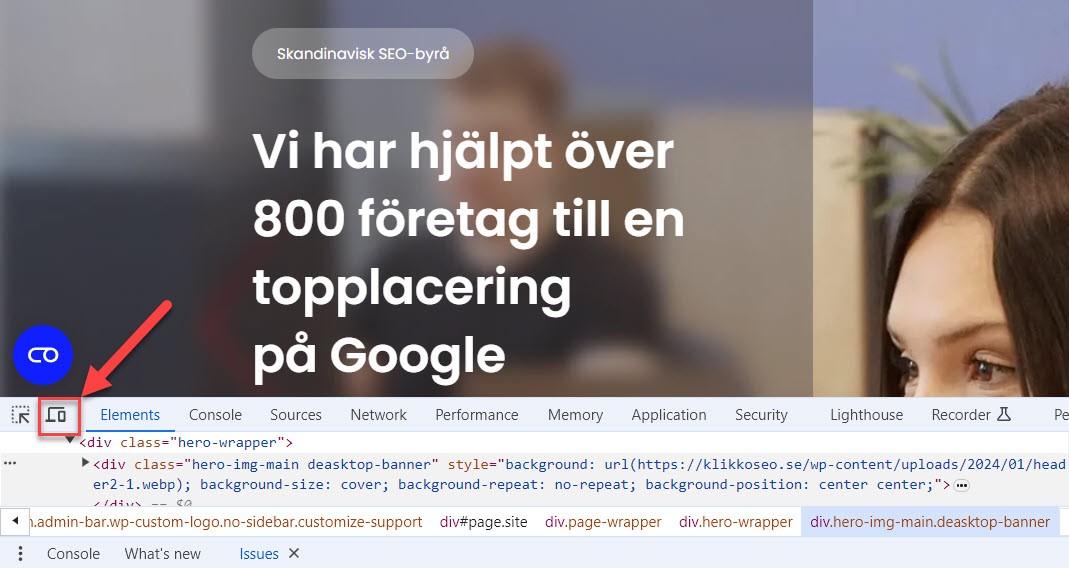
Next, you can view how the webpage looks on mobile, and switch the simulated phone model here:
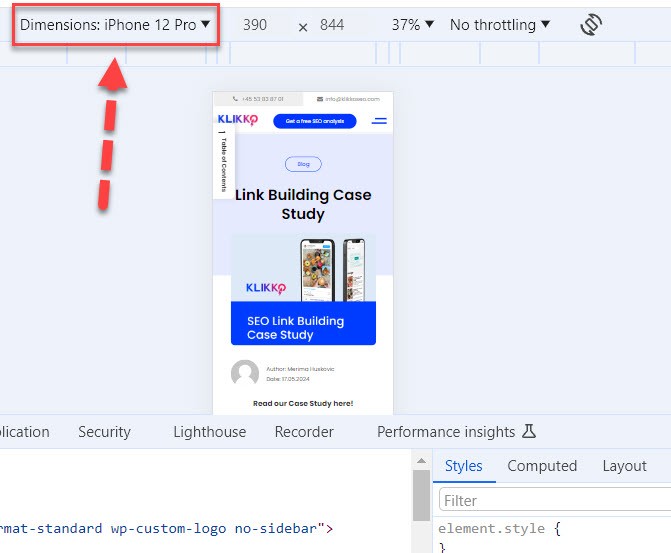
For mobile users, a fast site is particularly important as they often rely on their mobile connection when browsing. This could be especially crucial if your target audience is located in areas with poor connectivity/coverage.
Use Google’s PageSpeed Insights or Google Lighthouse to check how quickly your site loads on mobile and for recommended actions to improve speed:
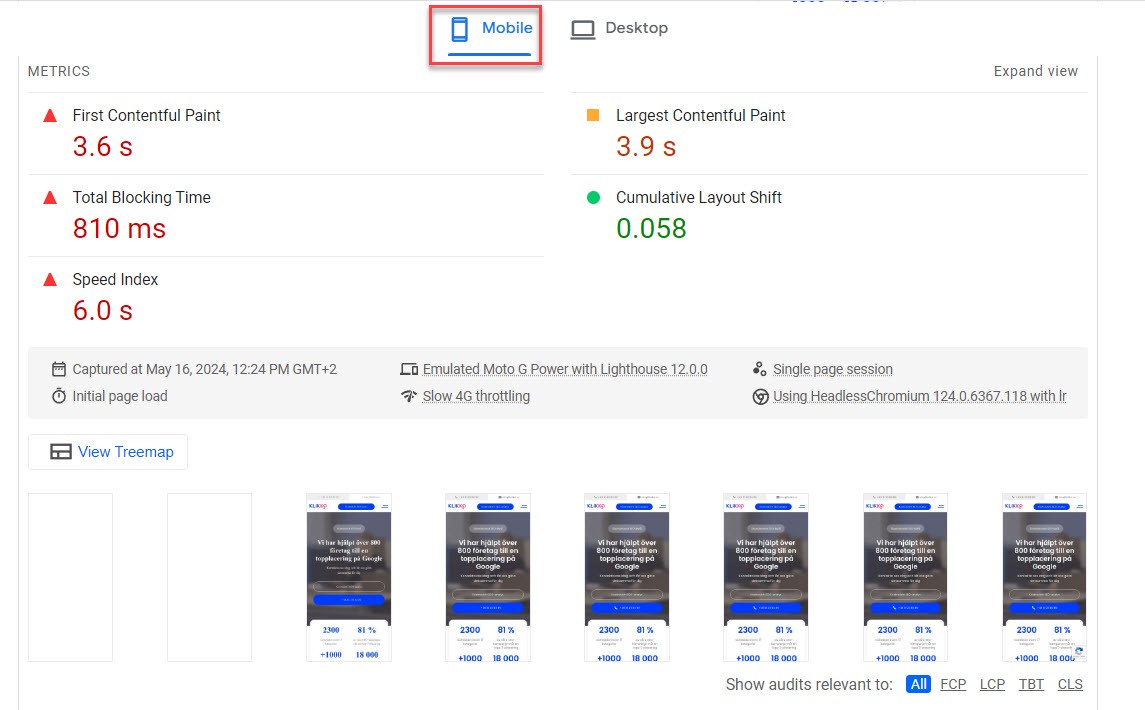
Google PageSpeed Insights
As mentioned earlier, you can also utilize other external tools like GTMetrix.
Structured data
To conclude, we’ll discuss structured data. Structured data is a dataset organized and formatted in a specific way on a webpage.
In a SEO context, it refers to data presented in a standardized format to convey information about webpage content to search engines. It can range from ingredients and cooking times for recipes to store hours, product prices and ratings, and more.
Why is it important?
Structured data helps search engines understand the content on webpages so they can ultimately produce richer and more personalized search results, known as “Rich Results“. This is helpful for users and gives websites which have implemented structured data a better chance of attracting visitors. Below, see an example of search results enriched with structured data:
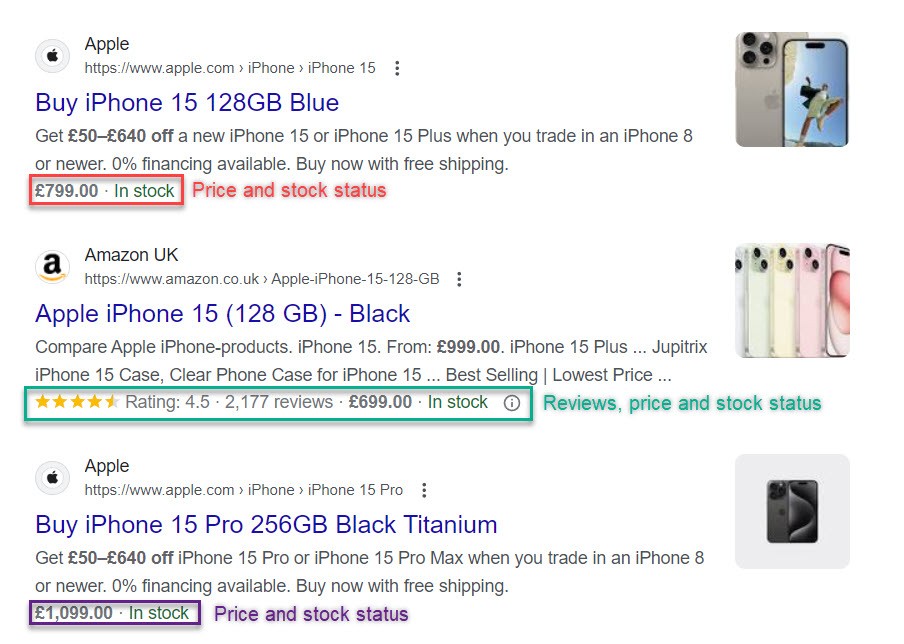
Rich Results for the keyword “iphone 15 price”
How do you implement structured data?
To communicate structured data to a browser, a vocabulary (words that make sense to the recipient) and a format (rules on how the words are used to convey the message) are needed.
The most common vocabulary, universal for major search engines, is schema.org. You can find more information about it on their website: https://schema.org/.
JSON-LD is the most common syntax recommended by Google
Structured data is implemented directly in the webpage code, and there are numerous types of Rich Results you can optimize for. Here, you can see Google’s own documentation on the different types.
After implementation, you should test your page in the Rich Results Test to ensure it works correctly.
Conclusion
When working with technical SEO, it’s critical to understand the work never truly ends. The digital landscape is perpetually evolving. Google consistently launches new features and best practices to keep abreast of.
It’s a good idea follow Google’s own blog on search engine developments or our personal favorites, Search Engine Journal and Search Engine Land.
And obviously, we recommend signing up to our own newsletter, where we will deliver the latest news to you – in English.
If you sense you need help with your technical SEO, feel free to contact us for a complimentary, basic analysis.
